Today I would like to show you how it is easy to begin with this tool.
First launch
- Download an ElasticSearch archive on http://www.elasticsearch.org/download/
- Extract the archive
- Launch elasticsearch :
$ ./bin/elasticsearch -f
[2013-07-12 17:09:08,776][INFO ][node ] [Centurius] {0.90.2}[2741]: initializing ...
[2013-07-12 17:09:08,785][INFO ][plugins ] [Centurius] loaded [], sites []
[2013-07-12 17:09:11,253][INFO ][node ] [Centurius] {0.90.2}[2741]: initialized
[2013-07-12 17:09:11,253][INFO ][node ] [Centurius] {0.90.2}[2741]: starting ...
[2013-07-12 17:09:11,372][INFO ][transport] [Centurius] bound_address {inet[/0.0.0.0:9300]}, publish_address {inet[myComputer/127.0.0.1:9300]}
[2013-07-12 17:09:14,470][INFO ][cluster.service] [Centurius] new_master [Centurius][cuT7Cb_eQbaHyQ9fW9aCng][inet[myComputer.local/127.0.0.1:9300]], reason: zen-disco-join (elected_as_master)
[2013-07-12 17:09:14,514][INFO ][discovery] [Centurius] elasticsearch/cuT7Cb_eQbaHyQ9fW9aCng
[2013-07-12 17:09:14,542][INFO ][http ] [Centurius] bound_address {inet[/0.0.0.0:9200]}, publish_address {inet[myComputer.local/127.0.0.1:9200]}
[2013-07-12 17:09:14,543][INFO ][node ] [Centurius] {0.90.2}[2741]: started
[2013-07-12 17:09:14,595][INFO ][gateway ] [Centurius] recovered [0] indices into cluster_state
ElasticSearch is now running! You can check that by going to http://localhost:9200 in your web browser. Centurius is the name of the launched instance. You can override it by changing the property node.name in the elasticsearch.yml file.
You should only try to change the configuration if you encounter a problem. The default configuration is good enough to bring the server in production.
Basic queries
ElasticSearch provides a restful API allowing to create, search or delete documents. So to create documents you have to do a HTTP POST or PUT request, to search documents you have to do a GET request, and to delete documents you have to do a DELETE request.Create a document
I want to create a simple database containing e-commerce products. Each document is created in a specific index under a specific type. From whose coming from SQL world like me, the index is similar to a SQL database instance whereas the type is similar to a SQL database table. To store my products documents, I call the index “catalog” and the type “product”. The document content must be in JSON.
To create a document, you have to respect the following syntax :
$ curl -XPOST 'http://<host name>/<index>/<type>/' -d '{<your json document>}'For example :
$ curl -XPOST 'http://localhost:9200/catalog/product/' -d '{
"title" : "Ipad 2", "manufacturer" : "Apple", "submissionDate" : "2013-07-12",
"text" : "tablette tactile" }'
{"ok":true,"_index":"catalog","_type":"product",
"_id":"iZ_SSvyBRbOBYeRHWIjSaA","_version":1} Congratulations, you have created your first document. Each document has an unique identifier. Here the identifier has been generated automaticaly because I did a POST request, it is "iZ_SSvyBRbOBYeRHWIjSaA".
List all documents
To check that the document has been correctly created, you can list all the indexed documents with the following command :
$ curl -XGET 'http://localhost:9200/catalog/_search'
{"took":2,"timed_out":false,"_shards":{"total":5,"successful":5,"failed":0},
"hits":{"total":1,"max_score":1.0,"hits":[{"_index":"catalog","_type":"product",
"_id":"iZ_SSvyBRbOBYeRHWIjSaA","_score":1.0, "_source" : { "title" : "Ipad 2",
"manufacturer" : "Apple", "submissionDate" : "2013-07-12",
"text" : "tablette tactile" }}]}}
Search documents by term
If you want to search every document with a title equals to "ipad" :
$ curl -XGET 'http://localhost:9200/catalog/product/_search' -d '{
"query" : {
"match" : {
"title" : "ipad"
}
}
}'
Please note that you can search documents in an entire index (/catalog) or just on a type (/catalog/product).
Search documents with wildcard query
If you want to search every document with a title starting with "ip" :
$ curl -XGET 'http://localhost:9200/catalog/product/_search' -d '{
"query" : {
"wildcard" : {
"title" : "ip*"
}
}
}'
Search documents with fuzzy query
If you want to search a document from a term potentially misspelled, you can do a fuzzy query. For example the following query allows to search the products with a title like ipod or ipad :
$ curl -XGET 'http://localhost:9200/catalog/product/_search' -d '{
"query" : {
"fuzzy" : {
"title" : "ipud"
}
}
}'
Delete a document
If you want to delete a document, you have to do a DELETE HTTP request :
$ curl -XDELETE 'http://localhost:9200/catalog/product/_query' -d '{
"match" : {
"title" : "Iphone 5"
}
}'
Understand ElasticSearch clustering
The ElasticSearch-Head plugin allows to see the cluster state. To install it :$ ./bin/plugin -install mobz/elasticsearch-head
-> Installing mobz/elasticsearch-head...
Trying https://github.com/mobz/elasticsearch-head/zipball/master... (assuming
site plugin)
Downloading ...........DONE
Identified as a _site plugin, moving to _site structure ...
Installed head
Now, without restarting ElasticSearch, you can check the cluster state here : http://localhost:9200/_plugin/head.
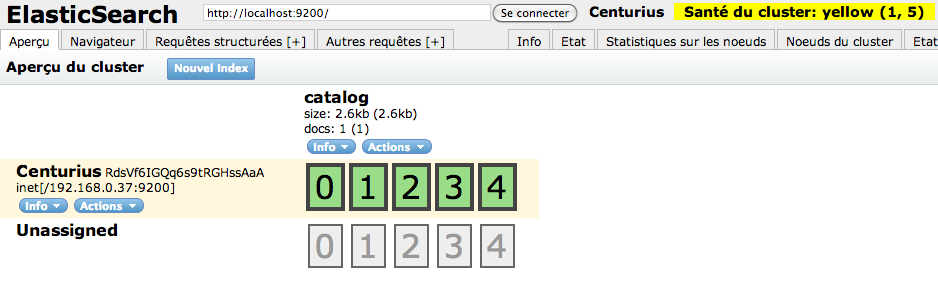
We can find our ElasticSearch instance called Centurius. This instance is composed, by default, of five shards (property index.number_of_shards). Each shard is a Lucene instance automatically managed by ElasticSearch. When you create a document, the document id is used to determine in which shard it must be stored.
Now we can launch a new instance of ElasticSearch (elasticsearch -f in a new tab of your console). If you refresh the ElasticSearch-Head page, you constat that a new instance apperead in the cluster :
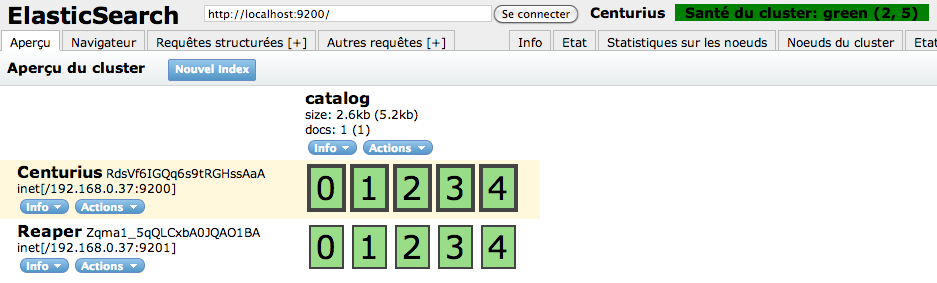
If you check the logs of the first instance :
[2013-07-12 17:35:42,209][INFO ][cluster.service] [Centurius] added
{[Reaper][Zqma1_5qQLCxbA0JQAO1BA][inet[/192.168.0.37:9301]],},
reason: zen-disco-receive(join from node[[Reaper][Zqma1_5qQLCxbA0JQAO1BA]
[inet[/192.168.0.37:9301]]])
The new ElasticSearch instance has been automatically discovered by unicast (by default). Each ElasticSearch instance from the same network and with the same cluster name is gathered in the same cluster. You can change the cluster name of an instance in the file config/elasticsearch.yml, property cluster.name.
Now let's add a third instance of ElasticSearch :

By default, each shard is replicated twice (property index.number_of_replicas) : one primary shard used for read and write operations, and one replica shard used for read operations.
Here the node Centurius contains the primary shards 1, 3 and 4. The node Noh-Varr contains the primary shards 0 and 2. Finally, the node Reaper contains only replica shards.
Conclusion
I hope this thread gave you the basis to work with ElasticSearch and to understand its clustering mechanism. Don't hesitate to play with ElasticSearch, change its properties and do more complicated queries! Besides this thread, a good way to start with this tool and to understand every concept is the ElasticSearch glossary page. Have fun!